오늘부터 매주 월요일에는 인공지능과 관련된 기본적인 개념들에 대해 저만의 방식으로 소개해드릴 예정입니다. 첫 번째 키워드는 '머신러닝과 딥러닝'입니다.
머신러닝 vs 딥러닝
어렸을 때 '공부가 필요 없는 세상'이 오길 꿈꿨던 적이 있어요. (당시에는 "공부 = 암기" 공식이 적용되던 때였습니다.) 지금은 그 꿈이 이뤄졌습니다. 인공지능에게 뭐든지 물어보면, 금방 답을 찾을 수 있는 시대가 됐기 때문입니다.(뭉뚱그려서 표현해서 죄책감이 들지만, 정답이 존재하는 문제에 대해서 평균 이상 수준으로 답을 찾을 수 있게 됐습니다.) 그렇다면 인공지능은 어떻게 그렇게 많은 지식을 '공부'할 수 있었을까요?
머신러닝과 딥러닝은 인공지능 어떻게 공부할 수 있었는지를 설명해주는 개념이라 할 수 있습니다. 이미 '러닝'이라는 글자 자체에도 써있듯이 말이죠.
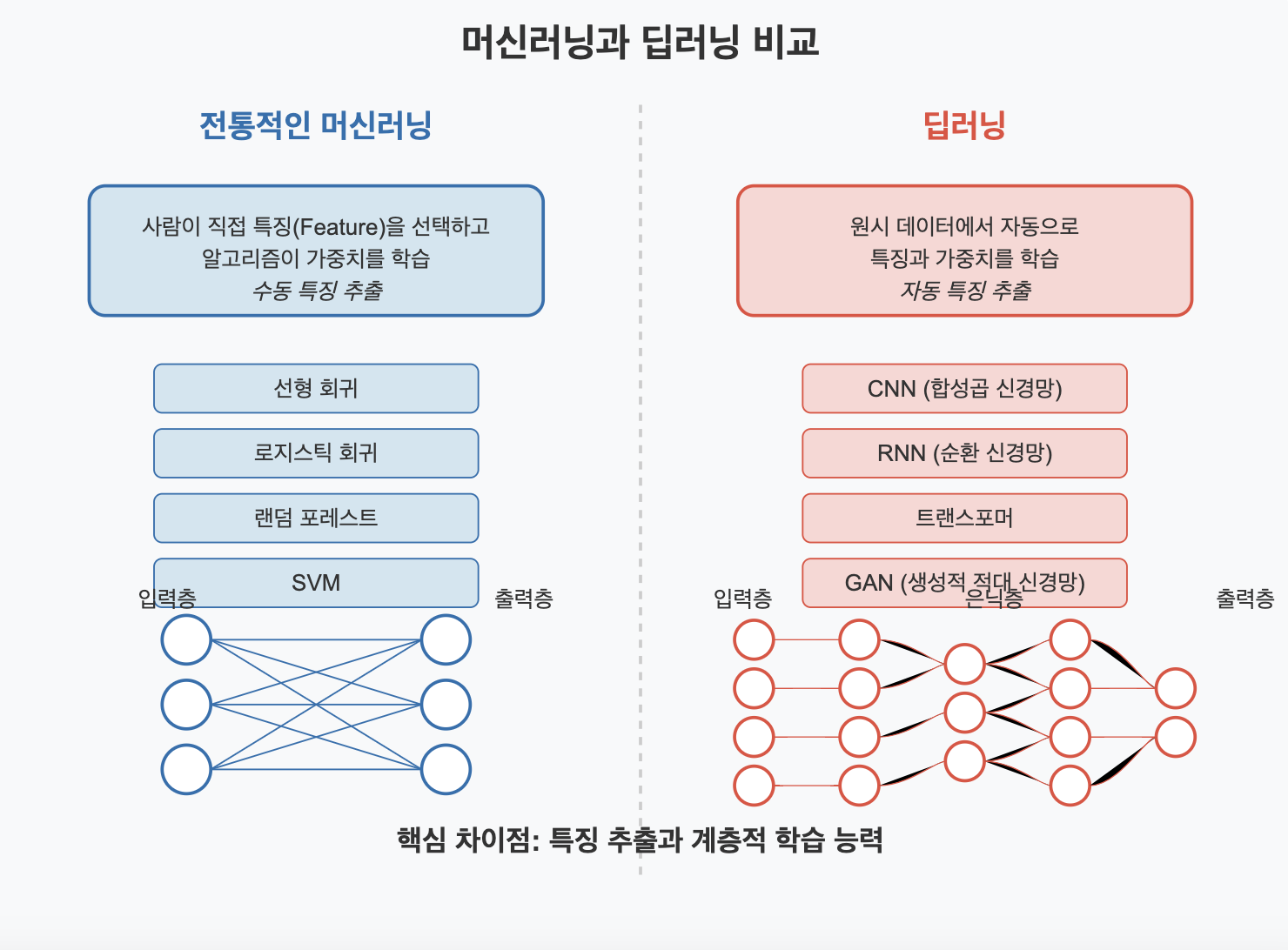
머신러닝은 전통적으로 사람이 규칙을 만들고 기계가 연산을 하는 방식입니다. 올해 부동산 가격을 예측하는 일을 생각해볼까요? 사람이라면 부동산 가격에 영향을 미치는 지표들과 실제 거래 데이터들을 분석해서 상관관계를 찾아 예측을 하려고 할 것입니다. 머신러닝도 이와 비슷하게 작동합니다. 사람이 부동산 가격에 영향을 미칠 주요 특징들을 잡아서 제공하면, 기계는 이 특징에 랜덤하게 가중치를 부여해 계산을 하고 정답(실제로 거래됐던 과거 부동산 가격)과 비교합니다. 기계가 예측한 값과 정답을 비교해 오차를 계산하고, 오차가 최소가 되도록 하는 최적의 '연산'을 찾아내는 것이 기계가 하는 일입니다. 중요한 것은, 부동산 가격을 예측하기 위해 사람이 직접 "지역", "건축연도", "면적" 등과 같은 특징들을 선별해서 데이터를 기계에 준다는 점입니다.
하지만 딥러닝은 다릅니다. 사람이 직접 특징을 뽑지 않습니다. 사람은 입력 데이터와 출력 데이터만 줍니다. 특징을 뽑고 연산을 하는 과정 모두 기계가 합니다. 다시 부동산 가격 예측하는 예로 돌아가보겠습니다. 사람은 매물 정보와 실제 거래 가격만 제공하면, 기계가 어떤 특징(위치, 층수, 교통 등)이 중요한지 파악하고 가중치를 부여합니다. 아마 처음에는 엉터리 예측을 하겠지만, 수많은 데이터를 학습하면서 "지하철과 가까우면 가격이 오른다", "남향이 비싸다"와 같은 패턴을 발견하게 됩니다. 편한 것 같지만, 연산량이 엄청나게 많고 방대한 데이터가 필요합니다.
머신러닝이 사람이 준 특징에서 패턴을 찾는다면, 딥러닝은 주어진 원시 데이터에서 사람이 찾지 못한 특징이나 패턴을 발견할 수 있습니다. 딥러닝은 복잡한 패턴들도 자동으로 학습할 수 있습니다. 이미지를 인식하는 경우에 단순한 선과 모서리에서 출발해 점점 복잡한 형태와 객체를 인식해나가는 '계층적' 특징을 학습합니다. 머신러닝이였다면 이러한 계층적 학습이 아닌 미리 정의된 특징을 가지고 학습을 하게 됩니다. 즉, 머신러닝은 전문가의 개입이 더 필요한 학습 방법이고 딥러닝은 막대한 데이터를 가지고 스스로 복잡한 패턴을 찾아가는 방법입니다.