이번 레터에는 이런 내용들이 담겨 있어요.
👉 Baseline: AI 모델의 ‘파인튜닝’ 개념에 대해 알아봤어요.
👉 Playground: 오픈소스 모델들을 다운받을 수 있는 허깅페이스를 구경해요.
👉 What's News?: 최신 뉴스들을 큐레이팅했어요.
|
|
|
으악! 구독 지옥에 빠졌습니다. 넷플릭스, 네이버플러스, 쿠팡, 챗GPT, 클로드, 마이크로소프트 오피스365, Google Drive 등등 너무 많죠! 특히 LLM 구독료는 꽤 비싼 편인데요. 그래서 저는 이런 생각을 한 적도 있습니다.
오픈소스로 된 무료 모델을 내 노트북(로컬)에 다운받아서 사용하면 어떨까?! 인터페이스는 조금 구리겠지만요. 사실 이런 개인적인 이유가 아니더라도, 회사 차원에서 AI 서비스를 만들 때에도 범용 LLM 대신 무료 모델을 다운받아 추가적인 학습을 시켜서 사용하는 것을 고민할 수 있습니다. (범용 LLM들은 사용하는만큼 돈을 내야하는데 그게 꽤 비싸잖아요.)
모델을 있는 그대로 사용하지 않고, 다운받아서 내가 바꿔서 사용한다? 뭔가 떠오르는 것이 있죠. 바로 튜닝입니다. 순정 자동차를 내 스타일대로 개조하는 것 처럼요. |
|
|
# 파인튜닝(Fine-tuning)
튜닝. 순정 상태에서 바꾸는 것을 의미하죠. AI 세계에서도 마찬가지입니다. 학습이 완료된 모델(pre-train 된 모델)을 가져와 내가 원하는 대로 바꾸는 것을 튜닝이라 합니다.
어떻게 바꾸냐고요? 만약 번역 작업에 특화된 AI 모델을 만들고 싶다면 기존 모델을 가져와 번역 데이터를 넣고 추가 학습을 시킵니다. 모델은 추가 학습을 통해 모델 내 가중치, 파라미터가 바뀝니다. 이를 파인튜닝이라고 합니다. 즉 내가 원하는 특정 태스크(작업)이나 도메인에 맞춰 추가 학습을 시켜 기존 학습된 파라미터에 미세 조정을 가하는 것입니다. 모델을 내가 원하는 작업이나 분야에 특별히 더 잘 적응시키기 위해서요.
지금처럼 챗gpt나 클로드, 제미나이 같은 거대한 LLM이 나오기 전에는 각각의 자연어 처리 태스크에 맞춘 작은 모델들이 많이 개발되었습니다. BERT라는 모델이 대표적입니다. 트랜스포머 인코더 구조를 기반으로 만든 대표적인 사전 훈련 모델입니다. 트랜스포머 구조로 여러 레이어를 쌓아 사전 학습 시킨 BERT를 다운로드 받은 뒤에 번역 데이터를 왕창 넣고 추가 학습을 시켜 ‘번역 전문 모델’을 만드는 방식이죠.
파인튜닝의 두 가지 방법:
Full Fine-Tuning과 Parameter-Efficient Fine-Tuning(PEFT)
튜닝에는 크게 두 가지 방법이 있습니다. 모델 내 전체 파라미터를 업데이트하는 풀 파인튜닝과 일부 파라미터만 업데이트하는 PEFT입니다.
전체 파라미터를 업데이트하면 모델이 새로운 데이터에 완전히 맞춰지므로 좋은 성능을 기대할 수 있습니다. 기존 지식이 아닌 아주 특수한 작업에서도 효과적이고요. 대신 풀 파인튜닝은 GPU와 메모리가 많이 필요하며, 학습시키는 시간도 오래 걸립니다. 파라미터 수가 많아 대규모 모델을 풀 파인튜닝하는 것은 현실적으로 어렵기도 하고요. 게다가 사전 학습된 지식을 잃는 현상(catastrophic forgetting)이 발생하기도 합니다.
반면 PEFT는 일부 파라미터(어댑터, LoRA, 프롬프트 등)만 추가하거나 조정하여 모델을 미세조정합니다. GPU 리소스가 부족하거나 비용이 제한적일 때에도 학습을 시킬 수 있습니다. 게다가 전체 파라미터 대비 극소수만 학습하기 때문에 속도가 빠르고, 기존 모델 구조를 그대로 유지하여 배포도 용이합니다. 적은 데이터만으로도 튜닝이 가능하고요. 대신 풀 파인튜닝보다는 성능이 떨어질 수 있습니다.
챗GPT의 등장 이후 많은 LLM들이 단순한 질의응답, 요약, 번역 등의 작업에서 파인튜닝 없이도 충분한 성능을 냅니다. 하지만 범용 LLM이 아무리 강력하더라도 특정 도메인, 기업 고유의 데이터를 학습하지 않고는 전문 분야에서 충분한 성능을 내지 못합니다. 특수한 포맷이나 일관된 스타일을 유지하는 것도 어렵습니다. 게다가 상용 모델을 사용하는 것 또한 비용이 많이 발생합니다. 어쩌면 특정 모델을 PEFT 하여 좁은 영역에서 전문가급의 성능을 내게 하는 것이 훨씬 효율적일 수 있습니다.
튜닝의 끝은 순정이라고, 언젠가는 AI 범용 모델의 가치를 다시 느끼게 될 수도 있겠죠. 하지만 다양한 튜닝을 해 본 사람이 순정의 진가를 더 잘 아는 것처럼, 여러 모델을 직접 만져보고 개선해보는 경험 자체가 소중한 자산이 될 것 같습니다.
|
|
|
# AI계의 GitHub, 허깅페이스 탐색하기
그렇다면 이렇게 파인튜닝할 수 있는 모델,
그리고 파인튜닝된 모델들은 어디에서 찾을 수 있을까요?
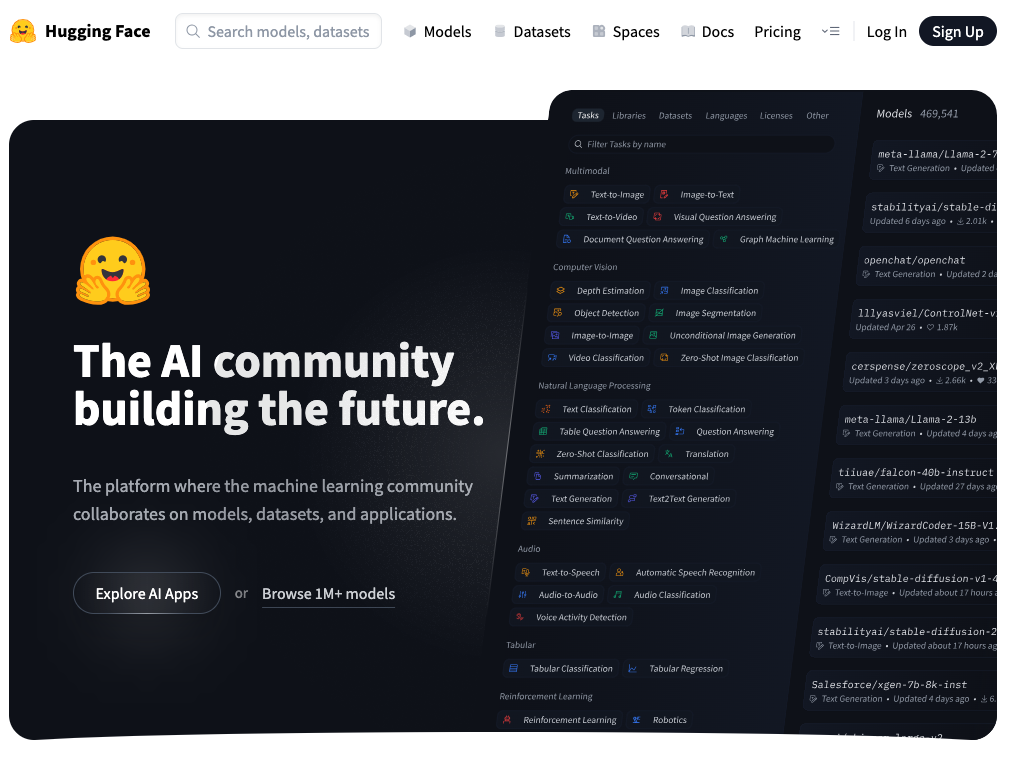
두 팔을 쭉 뻗어 안아주려고 하는 귀여운 이모지가 트레이드마크인 허깅페이스(Hugging Face). 이곳은 AI계의 GitHub라 불리는 곳입니다. 마치 개발자들이 GitHub에서 코드를 공유하듯이, AI 연구자와 개발자들이 모델, 데이터셋, 그리고 AI 애플리케이션을 자유롭게 공유하는 거대한 오픈소스 커뮤니티예요.
허깅페이스는 단순한 모델 저장소를 넘어 AI 민주화를 목표로 하는 플랫폼입니다. “모든 사람이 AI를 쉽게 사용할 수 있게 하자!”는 철학으로 복잡한 AI 기술의 진입장벽을 낮춰주는 역할을 하죠. (그래도 처음에 들어가면 뭐가 뭔지 모르겠고, 복잡하게 생겼습니다.)
허깅페이스 사이트 상단을 보면 Models, Datasets, Spaces, Docs 탭이 있습니다. |
|
|
- Models: AI 모델의 보물창고 📦
100만 개가 넘는 오픈소스 AI 모델들이 모여있는 곳이에요. 텍스트 생성, 이미지 인식, 음성 변환 등 거의 모든 AI 작업에 필요한 모델을 찾을 수 있습니다. DeepSeek R1 같은 최신 모델들도 빠르게 업로드되고 있어요.
- Datasets: 학습 데이터의 천국 📊
모델 학습에 필요한 다양한 데이터셋들이 정리되어 있습니다. 번역용 데이터, 감정분석 데이터, 이미지 데이터 등 원하는 분야의 데이터를 쉽게 찾아 다운로드할 수 있어요.
- Spaces: AI 체험관 🚀
Gradio나 Streamlit으로 만든 AI 데모 애플리케이션들을 체험할 수 있는 공간입니다. 모델을 직접 다운로드하지 않고도 웹에서 바로 테스트해볼 수 있어요. 마치 AI 모델들의 "시연장" 같은 역할이죠.
- Docs: 친절한 사용 설명서 📚
초보자부터 전문가까지, 허깅페이스 생태계를 활용하는 방법을 단계별로 설명해놓은 문서들이 있습니다.
무료 대화 모델을 다운로드 받아서 개인용 챗봇을 만든다거나, 번역 모델을 다운로드 받아 나만의 번역기로 사용해볼 수도 있어요. 모델은 로컬 환경에서 직접 돌려볼 수 있고, GPU와 메모리가 가능하다면 PEFT로 직접 튜닝에 도전해볼 수도 있습니다. 개인적으로 허깅페이스에 들어갈 때마다 없던 의욕과 아이디어도 마구 샘솟는 느낌입니다! |
|
|
요즘엔 무슨 일이?
기업
- 직장 복귀한 머스크, 156조 가치로 xAI 대규모 투자 라운드 준비(링크)
- 구글, 오픈 소스 모델 다운·실행하는 휴대폰 앱 출시(링크)
- 애플, 오픈AI 맞먹는 150B 추론 모델 개발...출시는 미정(링크)
- 질문 맞춰 최적 LLM 찾아주는 '라우팅' 챗봇 플랫폼 등장(링크)
- 삼성, 갤럭시 S26에 퍼플렉시티 AI 음성 비서 탑재 계약 임박(링크)
- 오픈AI, 챗GPT 'AI 슈퍼 비서' 계획 담긴 내부 문서 공개..."강력한 경쟁자는 메타"(링크)
- 허깅페이스, '오픈 소스' 휴머노이드 2종 공개...가격은 410만원(링크)
- 솔트룩스, 추론 모델 '루시아 3.0'·업그레이드 '구버' 공개(링크)
- "검색도 평등해야"…토종 AI 포털 '젤리아이' 베일 벗다(링크)
정부/정책
- 관심 꺼진 국가AI컴퓨팅센터, 요건 변경없이 강행…또 유찰되나(링크)
- 중국, 세계 첫 'AI 핵탄두 검증기' 개발…美-中 군축협상 흔드나(링크)
- "동남아판 챗GPT 만든다"…싱가포르, '멀티모달 LLM'에 '7천만 달러' 투입(링크)
학계
- "미세조정보다 RAG 개선이 더 효율적"...강화 학습 프레임워크 등장(링크)
- "AI, 인간처럼 의사소통 능력 자발적으로 개발할 수 있어"(링크)
- 오답 보상에도 AI 성능 향상하는 강화 학습…"정답 없어도 학습 가능"(링크)
- 르쿤 "AI와 인간 지능은 4가지 차이...월드 모델의 '추상화' 능력이 이를 메울 것"(링크)
- 동물과 대화하는 날 오나…AI, 고래 말 해독 중(링크)
사회
- "AI는 기술 역사상 가장 빠르게 성장...오픈AI도 추월 당할 수 있어"(링크)
- "AI 생산성 향상시키면 GDP 약 35% 늘어날 수도"(링크)
- "코딩은 기본"…시스템 통합 업계 업무 전 분야 AI 확대(링크)
|
|
|
오늘 뉴스레터 어떠셨나요?
의견을 남기고 싶다면 eddie.workwithai@gmail.com로 메일을 보내주세요. |
|
|
|