인공지능과 함께 만드는 AI 뉴스레터
2025년 5월 21일 수요일 |
|
|
이번 레터에는 이런 내용들이 담겨 있어요.
👉 AI 기초 개념들을소개하는 Baseline에서는, 토큰에 대해 알아봤어요.
👉 AI를 가지고 노는 Playground에서는,최대 토큰값을 조절한 프롬프트를 비교했어요.
👉 What's News?에서는 최신 뉴스들을 큐레이팅했어요. |
|
|
LLM을 사용할 때마다 (나도 모르게) 조용히 소비되고 있는 것이 있습니다. 바로 ‘토큰’입니다. 토큰은 AI 모델의 성능과 비용, 속도를 결정하는 핵심 요소인데요. 이번 레터에서 토큰이란 무엇이며, 실제 데이터와 사례를 통해 토큰을 어떻게 줄여서 사용할 수 있을지 정리해보았습니다.
# Token(토큰)과 Tokenizer(토크나이저)
토큰은 LLM이 텍스트를 처리하기 위한 기본 단위입니다. 간단히 말해서 텍스트를 작은 조각으로 나눈 단위라고 할 수 있죠. 토큰화를 하는 도구 또는 알고리즘을 토크나이저(Tokenizer)라고 부르는데, 이 토크나이저가 텍스트를 토큰으로 쪼갠다고 생각하면 됩니다.
지난 레터 중에 LLM의 작동 원리를 설명하면서 토큰을 그냥 단어라고 간단히 설명했었는데요. 영어에서는 이 말도 크게 틀리지 않은 것이, 평균적으로 영어 단어 하나가 대략 1.3 토큰으로 변환되기 때문입니다. 실제로는 토크나이저의 종류와 언어에 따라 토큰화 방식이 다르며, 한글에서는 단어 하나가 더 많은 토큰으로 쪼개지는 경우가 많습니다.
예를 들어 “I love dog”이라는 문장이 있습니다. 가장 단순한 방식으로 띄어쓰기를 기준으로 토큰을 나눌 때 ["I", "love", "dog"]으로 나뉩니다. 이를 공백 기반 토크나이저(Whitespace Tokenizer)라고 합니다. 이처럼 단어 하나가 토큰 하나로 매치될 수도 있지만, 토큰화 방식에 따라 더 작게 쪼개지는 경우도 있습니다. unhappiness”를 “un”, “happi”, “ness”로 나누는 것처럼요.
반면 한국어에는 형태소 분석 기반 토큰화가 더 적합합니다. “나는 강아지를 좋아해”라는 문장을 토큰으로 쪼갠다면 ["나", "는", "강아지", "를", "좋아", "해"]라고 조사와 어미 등을 분리하여 분석하는 것입니다. 이 외에도 다양한 토큰화 방식이 있으니 더 궁금하신 분들은 WordPiece 토큰화와 Byte-Pair Encoding (BPE), SentencePiece 토큰화 등을 검색해보시면 좋습니다.
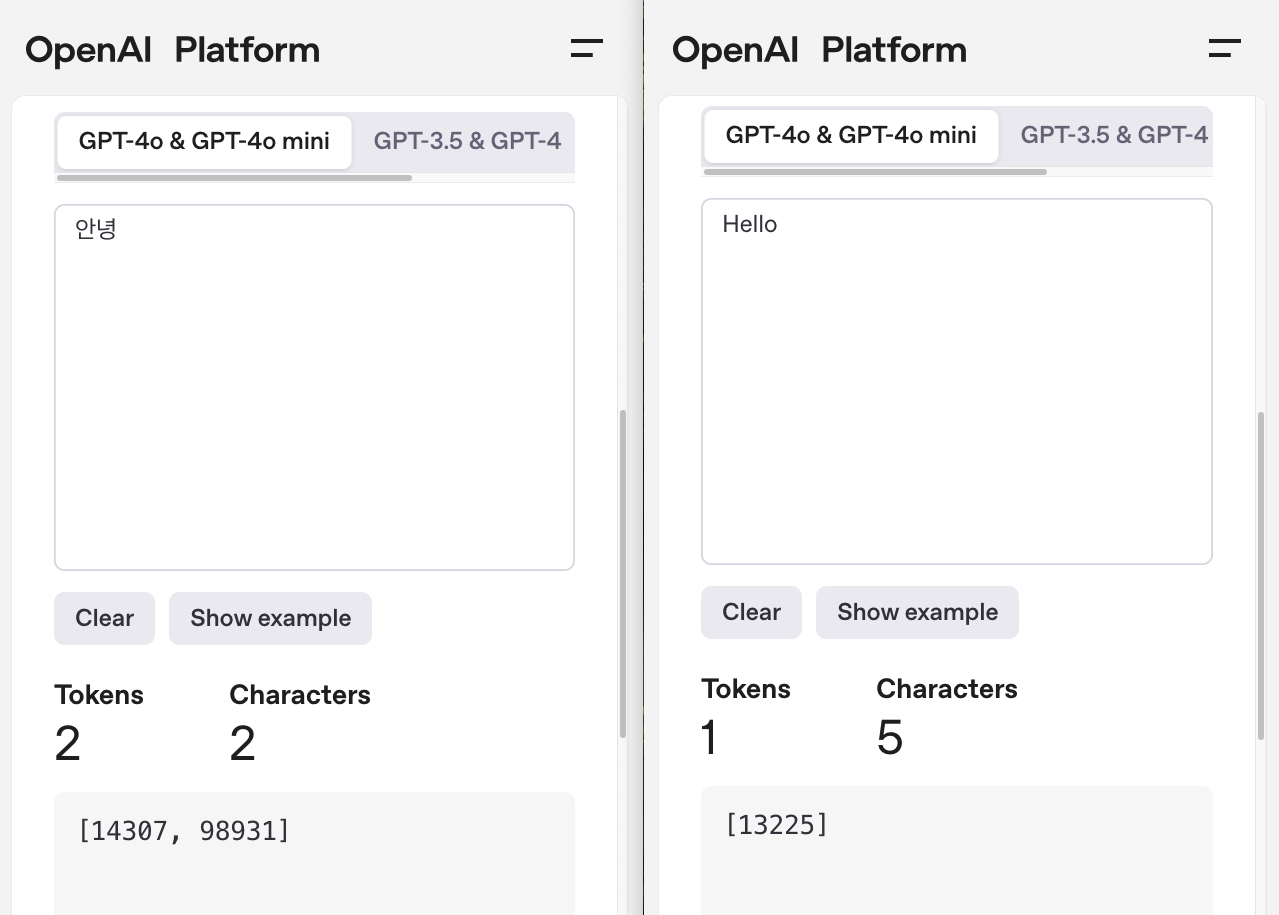
그렇다면 OpenAI 토크나이저로 영어로 hello, 한글로 안녕을 입력했을 때 토큰은 어떻게 쪼개질까요? |
|
|
한글로 안녕은 “안”과 “녕” 두 토큰으로 나뉘고, 반면 영어는 하나의 토큰이 나옵니다. 참고로 가장 아래에 [ ] 안에 들어있는 숫자는 각 토큰을 숫자 데이터(ID)로 바꾼 값입니다. 이 숫자 ID가 실제로 AI 모델이 처리하는 데이터입니다. 토크나이저는 텍스트를 토큰으로 쪼개고, 토큰에 부여된 숫자로 변환까지 해주는 역할을 합니다.
가장 단순한 “안녕” 예시에서도 볼 수 있듯이 한글은 영어보다 토큰을 더 많이 사용합니다. 이렇게 “토큰을 더 많이 사용한다”는 것에는 치명적인 단점이 하나 있었으니! 토큰을 많이 처리할수록 계산해야할 것들이 많아지고 API 사용 시 비용도 올라갑니다. 또한 입력과 출력 토큰의 비용도 달라 이 점도 고려해야 하죠.
그렇다고 토큰을 무작정 아낄 수만도 없습니다. 출력 결과와 품질이 악화될 수 있기 때문입니다.
뭐든지 적당히가 중요한 법! 적당한 토큰을 사용하여 최적을 답변을 얻는 것이 중요하겠죠? |
|
|
# 토큰을 제한하면 AI 답변은 어떻게 바뀔까?
토큰 제한이 답변의 품질에 어떤 영향을 미칠까요? 친구가 "주말에 뭐했어?"라고 물었는데, 딱 3단어로만 대답해야 한다면? "영화보고. 밥먹고. 잤어." 정도겠죠? 하지만 제한 없이 말할 수 있다면 "주말에 데빌스 플랜2를 봤는데, 첨에는 그래도 괜찮았거든? 근데 중간까지 보다가 너무 화나서 꺼버렸어."처럼 더 생생한 이야기를 할 수 있습니다.
AI의 토큰 제한도 이와 비슷한 면이 있습니다. 토큰 제한이 적으면 AI는 짧고 건조한 답변만 제공하고, 미묘한 뉘앙스와 맥락은 쏙 빠지게 됩니다. 반면 충분한 토큰이 주어진다면 깊이 있고 포괄적인 답변을 만나볼 수 있죠. 실제로 챗gpt에게 토큰 제한을 걸어주면서 답변이 어떻게 달라지는지 살펴보겠습니다.
먼저 오픈AI Playground에 들어갑니다. 기사 내용을 요약하는 작업을 시켰고요. gpt-3.5-turbo 모델을 사용하여 temperature=1, top-p=1을 유지한 채 max token 값만 조절했을 때 답변의 결과를 비교해보겠습니다. (참고로 3.5 모델은 max token으로 최대 4096까지 설정할 수 있습니다. 중간에 gpt가 답변하다가 짤리는 경우가 바로 max token 때문입니다.) |
|
|
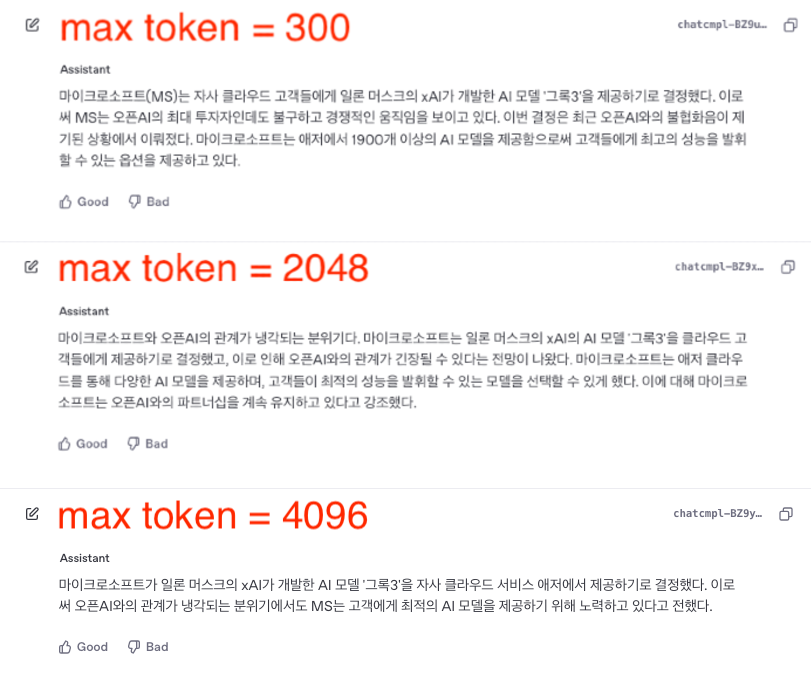
max token을 300, 2048, 4096으로 바꿔가며 출력을 비교해보았습니다.
max token = 300일 때에는 기사 내용의 표면적이고 기본적인 사실에 집중하여 요약한 것을 볼 수 있습니다. 반면 2048로 늘리자 기사 전체 맥락을 이해하고 정보를 요약한 모습입니다. 4096 최대값으로 늘렸을 때 답변의 길이가 가장 짧아지면서 동시에 포괄적인 내용을 함축적으로 생성했습니다.
여러분은 어떤 답변이 가장 마음에 드시나요? |
|
|
일반적으로 토큰 제한이 낮을 때 AI 모델은 핵심 정보만 제공하고 미묘한 뉘앙스와 맥락이 누락된다고 알려져 있습니다. 반면 충분한 토큰이 주어진다면 깊이 있고 포괄적인 답변이 생성됩니다.
하지만 여기서 중요한 건 '토큰 제한'만이 아닙니다. AI 모델에 입력할 수 있는 토큰의 양에도 한계가 있어요. GPT-3.5는 약 4,096 토큰, GPT-4는 8,192~32,768 토큰까지 처리할 수 있죠. 또한 모델이 입출력하는 토큰의 양에 따라 비용이 결정된답니다. 특히 API로 LLM을 사용할 때는 입력 토큰과 출력 토큰에 각각 다른 가격이 책정되기도 해요. 그러니 효율적으로 사용하려면 입력 토큰을 현명하게 조절해야 합니다.
예를 들어, “영어 공부 도와주는 AI 챗봇”을 만든다고 가정해보겠습니다. GPT-3.5 모델을 사용한다면, 챗봇에게 "너는 영어 선생님이야. 문법 오류를 찾아주고, 자연스러운 표현으로 바꿔줘. 항상 친절하게 대답해줘." 같은 지시를 해야 할 거예요.
여기에 수많은 영어 문법 규칙, 자연스러운 표현 예시, 다양한 상황별 대응법 등을 추가하면 어떻게 될까요? 토큰도 쭉쭉 늘어나고... 사용자가 질문 한 번 할 때마다 우리의 지갑도 쭉쭉 얇아지겠죠? 그래서 토큰을 조금만 사용하면서도 비슷한 품질의 답변을 받을 수 있도록 만드는 것이 중요합니다!
앞으로도 더 강력한 AI 모델이 계속 등장할 테지만, 강력한 성능만큼 비용도 높아질 수 있어요. 컨텍스트 창(처리할 수 있는 토큰 양)은 늘어나고 토큰화 방식은 더 효율적으로 변하겠지만, 여전히 '현명한 토큰 사용'은 중요한 과제로 남을 것입니다.
결국 우리가 해결하려는 문제가 무엇인지 명확히 정의하고, 그에 맞는 토큰 최적화 전략을 세우는 것이 핵심이 될 것입니다. 마치 한정된 예산으로 여행 계획을 세우듯, AI와의 대화도 토큰이라는 '예산'을 효율적으로 사용하는 법을 배워야 할 때입니다! |
|
|
요즘엔 무슨 일이?
기업
- 국내 대표 AI 기업들, 산단 찾아 산업현장 'AI 전환' 컨설팅(링크)
- "AI로 만든 콘텐츠입니다"⋯네이버 'AI 활용 콘텐츠' 표시 도입(링크)
- 미국 국회, 엔비디아 칩 위치 추적법 발의(링크)
- "엔비디아, 상하이에 R&D 센터 설립...중국 내 영향력 유지할 것"(링크)
- 흔들리는 오픈AI·MS 동맹...MS, 머스크의 AI 모델 제공 시작(링크)
- 오픈AI, 코딩 AI 에이전트 '코덱스' 출시..."바이브 코딩 다음 단계로 나갈 것"(링크)
- 깃허브, 코딩 에이전트로 개발 생태계 재편…'AI 팀원' 생긴다(링크)
- 구글, '제미나이 나노' API 공개…"온디바이스 이상의 기능도 지원"(링크)
- 톰슨로이터, 전문직 분야의 생성 AI 활용 보고서 발표(링크)
정부
- 정부·기업, K-온디바이스 AI 반도체 개발…1조원 규모 프로젝트(링크)
- 광주시 공무원 48% "생성형 AI 쓴다"…'보고서 작성' 70%(링크)
학계
- [사이테크+] 사람-AI 토론 능력 비교해보니…"GPT-4가 더 설득력 있어"(링크)
- MIT, 노벨상 수상자가 극찬한 'AI 생산성 향상' 논문 철회(링크)
- 구글, 새로운 '증강 미세조정' 제안..."ICL 일반화 강점에 미세조정 효율성 합쳐"(링크)
- 에임인텔리전스 "짧은 대화로 LLM 보안 취약점 발견할 수 있어"(링크)
|
|
|
오늘 뉴스레터 어떠셨나요?
의견을 남기고 싶다면 eddie.workwithai@gmail.com로 메일을 보내주세요. |
|
|
|